I published GL.iNet Slate 7, Tailscale, and Split-Routing Around the Great Firewall, a full technical writeup of the router-level setup I run in China: a Slate 7 carrying Tailscale as the default route to a Debian VPS exit node, with PBR sending Chinese CIDRs direct out the physical uplink and a dnsmasq split so CN domains resolve via AliDNS and everything else rides stubby DoT to Cloudflare. The post spends most of its time on the two war stories that took the longest to unstick: getting PBR's fwmark rules to win over Tailscale's exit-node rule, and hunting down GL.iNet's vpn_table stamping every LAN packet with 0x8000 and quietly breaking Google and YouTube. All the shell, nftables, and dnsmasq snippets embed live from a public gist, pinned to a revision so the post never drifts underneath its own code.
I have been busy lately, with a lot of things going on, but I have also been steadily building EDControlRoom. It is a commander-assist tool for Elite Dangerous, and I want to write more about the project soon: partly the tool itself, partly the gaming side of it, and partly the weird little lessons I have picked up from getting deeper into PC gaming again.
I am also working on a video for it, which has reminded me that editing is very much a skill that needs practice, but also one I really enjoy when I get back into it.
EDControlRoom in its current control-room shape.A small sneak peek at the video in progress.
I published A refresher on SwiftUI state management, async/await, and common patterns, turning a private set of interview-prep notes into a working refresher for the SwiftUI you actually meet in real codebases. It covers the pre-iOS 17 property wrappers next to their @Observable equivalents, async/await as the default for data loading, and the everyday shapes for networking, navigation, and error handling. The next entry in the Swift series, written for the version of me that has been away from SwiftUI long enough to want one page that catches him back up.
A new style of working with AI has been clicking for me lately: keeping several projects open at once, letting the main agent spawn off sub-agents per project, then hopping between them as work lands.
The glue is AGENTS.md and CLAUDE.md in each repo, which keeps every spawned agent oriented to that project's conventions while I focus on the next handoff. The loop in each project stays the same: pick a feature, write tests, document progress and findings as it goes, commit atomically.
It is genuinely engaging, more like conducting than coding, but it burns through tokens fast, especially on top-tier models like Opus 4.7 or GPT 5.5.
A few cost-saving strategies I've landed on: drop to lower-tier models where the work allows; instead of paying for the $100 tier at a single provider, take the $20 tier at both OpenAI and Anthropic and run them side by side; and lean into the fact that each model has its own strengths and weaknesses, just like any tool. It's the vim vs emacs thing again. There is no single best editor, only what suits the job in that moment (I use both, with evil-mode in Emacs as the vim layer).
Cut v1.0.0 of little-snitch-review-kit, a personal workflow I use for reviewing Little Snitch exports with an AI assistant.
The Little Snitch UI is great at intercepting one connection at a time, but it does not answer the longer questions I actually care about: what is this process talking to over a week, and which observed traffic has no explicit rule covering it.
This release bundles the analysis scripts (per-app rollups, uncovered pairs, denied traffic), the importable .lsrules builders (HaGeZi Pro and reviewed consolidation plans), and the docs and tests around the human-in-the-loop review workflow. The core constraint stays: scripts surface candidates, humans make the trust decisions.
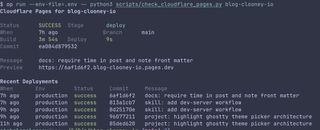
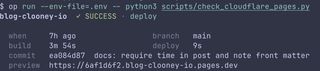
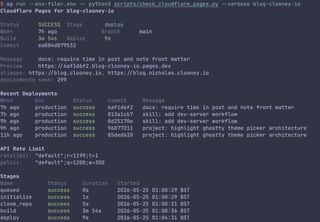
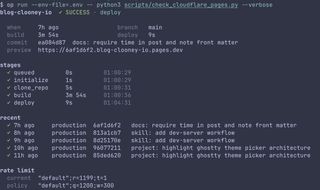
I've been iterating on scripts/check_cloudflare_pages.py, and this one ended up being a pretty clean example of where Claude currently feels stronger than Codex for TUI / UI design.
Codex got the script started and helped shape the core deployment-status workflow, but when it came to making the terminal output feel actually polished, especially across both the short and verbose views, Claude was noticeably better. At its best Codex still seems to struggle a bit with this kind of presentation work, so I ended up handing the UI pass over to Claude even though Codex had started the script.
View
Codex
Claude
Short version
Verbose version
Short and verbose output passes for the same Cloudflare Pages deployment-status script, comparing Codex against Claude.
I shipped v0.2.0 of ghostty-theme-picker, a two-column TUI theme browser for Ghostty that lets me compare dark and light themes side by side, star favorites, and keep jump history while I browse. The new release adds forward history and persistent browse state, but the engineering bit I especially like is leaning on a functional core and imperative shell, so most of the state transitions stay pure and surprisingly testable even though the app lives in the terminal. I also recorded a short demo below so I have a visual snapshot of how it feels in motion.
I keep staring at the new dotfiles project card image, generated by GPT, and getting a little mind-blown. Not only is every bit of text actually real text rather than the usual AI gibberish, the content itself coheres: the Ghostty window on the left shows plausible git aliases, the tmux pane in the middle has a believable folder listing, a git log, and a btop-style stats block, and the Emacs frame on the right has elisp in init.el and YAML in config.yml that kinda parse as real config.
And on top of that, Ghostty, tmux, and Emacs are exactly the tools I actually use, even if I haven't reached for those particular git aliases in a long, long time.
The dotfiles card image, with text that is somehow all real and coherent.
Still huh. Genuinely surprised by how far this has come.
I shipped v2026.05.2 of dotfiles as a follow-up polish pass on yesterday's tmux and Emacs reset.
This release adds a basic macOS Ghostty config, restores a bunch of the small Spacemacs habits I still wanted like fuzzy M-x, Helm buffer switching, avy motion, kj insert escape, project ripgrep search, restart and pasteboard bindings, plus YAML mode for config editing.
I also tightened the repo's own agent and release docs with AGENTS.md, CLAUDE.md, and a clearer note that these tags are chronological snapshots rather than semver, which makes the setup feel more intentional and easier to keep evolving.
I published Minimal OpenXR-OSX MVP: hello_xr on Quest from macOS, then turned it into a real end-to-end proof instead of leaving it as a plan. The note now covers the successful native macOS -> OpenXR-OSX -> Quest run, includes a short clip of the headset result, and explains that the runtime's built-in streaming server brought the Quest out of its blue standby screen into the actual hello_xr cubes scene before a later retest negotiated a real 90Hz path too. The visible drops and patchiness are documented with the important caveat that my wireless network environment was not tuned for this test, so I do not want to over-attribute those artifacts to the runtime alone.
I published Can CrossOver OpenXR Talk to OpenXR-OSX?, a follow-up note to the earlier Quest and Virtual Desktop dead-end notes. The useful part is that Elite reaching a Windows OpenXR runtime boundary in CrossOver does prove the app side is alive, but the bad news is that handing that off to OpenXR-OSX would need a custom Windows runtime shim, IPC bridge, and host-side adapter rather than a simple runtime switch.
I published Quest PCVR on Apple Silicon Mac via CrossOver and Virtual Desktop / CrossOver Findings, two notes that document the same dead end from slightly different angles. One explains why Quest PCVR from macOS through CrossOver fails at the runtime/compositor layer, and the other captures the bottle-level evidence from Virtual Desktop Streamer, SteamVR, and OpenXR probing. Together they are the version I wish I had before spending more time treating this like a tweakable game-config problem.
I published My AI-Assisted Terminal Setup: Subspace Emacs and a Tmux Layout Shortcut, the fuller write-up that ties together the tmux 70/20/10 layout and the move off Spacemacs into Subspace Emacs. It covers how Claude and Codex split the work between research and implementation, the tmux-as-TDD-harness approach that unblocked the layout binding, and the tmux/tmux#1839 discovery that finally let swap-pane preserve zoom state. This supersedes the two narrower notes from earlier today.
I published Building a Lightweight Emacs Config After Spacemacs, the fuller write-up I promised when I shipped the dotfiles update earlier today. It walks through why I left Spacemacs, what I kept (Evil, leader keys, Magit, Helm-style tracked file finding, early theme loading), and how the new ~/.emacs.d is organized as a small set of explicit modules instead of a framework.
I shipped v2026.5.1 of dotfiles, which pairs a nicer tmux workflow with the move away from the old Spacemacs setup into a smaller hand-rolled Emacs config. The tmux side gives me a one-keystroke 70/20/10 vertical layout plus a safe top-and-middle pane swap, while PR #2 keeps the core editor ergonomics I care about like Evil, leader keys, Magit, Helm-style tracked file finding, and early theme loading without the extra framework machinery. This is the point where the repo feels easier to understand and own, and I want to do a fuller write-up on the tmux and "Subspacemacs" workflow soon.
Published Tmux 70/20/10 Layout Shortcuts, a note about building a one-keystroke tmux layout that creates a stable 70/20/10 vertical stack and only allows pane swapping when the window is explicitly tagged as that layout. The useful part was not just the final run-shell binding, but the testing approach: using detached tmux sessions plus list-keys, list-panes, and show-options as a lightweight TDD harness before touching the real config. This is one piece of a broader terminal and editor workflow cleanup, and I want to write that larger tmux plus lightweight Emacs story up properly soon.
I shipped v1.34.0 of 11ty-subspace-builder, centralizing site and timeline copy in shared data files and reworking the templates to consume that data model cleanly. A lot of early Subspace work was intentionally optimized for speed and feedback loops rather than engineering neatness, but the project is big enough now that it needs better internal structure. This release feels like a step toward the right kind of guard rails: keeping the system flexible without leaving the growing timeline feature glued together by ad hoc copy and template assumptions.
Published Bypassing the Meta Horizon Link Drive Check in CrossOver, a write-up of the narrow binary patch that got Meta Horizon Link past its CrossOver drive eligibility check. The interesting part is that the patch did work, but only revealed the deeper problem: the installer depends on Windows service identity, driver, and runtime behavior that CrossOver does not provide cleanly.
Parsed relic catalog data flowing into the Neow's Cafe relic list and detail views.
I shipped the past couple of days of ProjectSpire work as Neow's Cafe v0.4.0, Catalog Service v0.4.0, and Parser Service v0.3.0. The old card-only parser and catalog names are now broader services, the parsers cover relics, potions, events, and monsters, and Neow's Cafe has live relic list and detail screens backed by the generated catalog instead of mock data. This is the first point where ProjectSpire feels less like a card browser and more like the start of a full Slay the Spire reference app.
I was pixel peeping ProjectSpire against the actual game, comparing the original Slay the Spire PNG in-game with my app's q85 WebP version generated from that same source art.
Somehow, despite the game having the full-resolution PNG available, the card looks worse in-game than it does in my app.
My educated guess is that the game has its own processing and rendering pipeline, with its own constraints and reasons for the final image quality tradeoff.
I tagged a ProjectSpire snapshot for 2026-05-11, but this one feels different because I barely did any of the implementation myself.
My Codex usage is nearly gone, so Claude carried most of the work while I was busy elsewhere: parsers for relics, potions, events, and monsters; shared parser utilities; tests; and a few devlogs.
I haven't built the UIs I need to verify Claude's parser work against the actual game properly. So I don't have that confidence in its work yet without the validation.
I miss Codex and the clearer feedback loop, the back and forth, and...
Most importantly my own deeper understanding of how everything ties together.
Blade of Ink now rendering its purple description text correctly.
I shipped a tiny Neow's Cafe v0.3.1 bug fix in ProjectSpire: purple was missing from the mapped text colors, so purple inline card text had nothing to resolve to. Now purple is part of the text color map, and cards like Blade of Ink can render their description highlight properly.
Published Where Do Codex's Cached Tokens Come From?, a note explaining why Codex can report millions of cached tokens after a run even when the actual prompt context is much smaller. The useful bit is that Codex's append-only agent loop keeps earlier messages as an exact stable prefix, so cache hits accumulate across repeated model calls in the same session.
Colored description text flowing from the catalog into Neow's Cafe card details.
I shipped a small combined ProjectSpire release: Card Catalog v0.3.0 and Neow's Cafe v0.3.0 now carry colored inline description text through the catalog and into the SwiftUI card views. The visible change is small, but it closes the loop from parsed game text to rendered card detail: upgraded values and highlighted terms now show with the same kind of color signal the game uses.
The catalog JSON now carries upgraded card values, and the app has a proper detailed card view where I can inspect those upgrades instead of only browsing the cards in their base form in the grid.
In the game, the numbers (17 and 5) in the text, would be highlighted with the color being green, because they are the upgraded from base values. That is next on my todo list.
Supress in the new detail view, with upgraded card data exposed from the catalog.
Almost running out of my weekly Codex / GPT token usage, so I switched to Claude for a few hours.
Somehow the experience feels much higher friction.
It likes to spend a long time thinking even for relatively simple tasks. For example: "write this devlog for me." It already had detailed guidance (ProjectSpire Devlogs CLAUDE.md) plus example documents in the same folder.
If it were GPT, it probably would have been done in seconds. Claude spent nearly a minute still "flabbergasting..." until I stopped it and asked what it was doing. Its response was essentially: "I was reading unnecessary documents."
Then there's the terminal behavior.
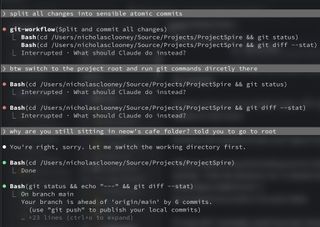
I wanted it to run some git commands, but it kept doing cd project-root && git ... everywhere. I genuinely do not understand why, because it can already execute commands from within the project context directly.
Claude, Claude, Claude...
I explicitly told it: "cd into the project root once and then run git commands directly without repeating cd." Nope. It still kept issuing (cd ... && git ...) commands until I corrected it a second time.
I'm genuinely having a hard time getting used to working with Claude. Curious what other people's experiences have been.
The parser now extracts keyword references from card text and populates a keywords field in the generated JSON, which the app picks up and renders as keyword pills on card detail views.
Status and curse cards were the most visibly broken before this: they had no keywords at all, which made a whole class of cards feel incomplete in the UI. The research behind this lives in Lab Doc 0014, which covers how keyword matching works against the game's localization data.
Neow's Cafe with the new light and dark app themes side by side.
I shipped another Neow's Cafe UI pass in ProjectSpire, focused on turning the app's visual styling into reusable systems instead of one-off view code. The work in the May 7 snapshot registers the app fonts as a typography system so I can use consistent text styles anywhere in SwiftUI, and adds explicit light and dark themes for the card catalog UI. It is a small-looking change, but it gives the app a much cleaner foundation for future screens.
It uses ProjectSpire as the working example: instructions as project memory, plans for intent, Captain Logs for collaboration taste, devlogs for technical history, and skills or workflows for repeated mechanical steps.
The useful idea is that the repo should accumulate context as it is used, so the human still supplies the judgment, but the surrounding system gets better at carrying that judgment forward.
I shipped v1.33.0 of 11ty-subspace-builder, adding wrap toggles to Markdown code blocks and GitHub embeds. Markdown code blocks now wrap by default, including Markdown files rendered through GitHub embeds, while collapsed GitHub embeds still allow long lines to scroll horizontally. I also added a draft regression page for long GitHub and Markdown code lines so this behavior has a concrete page to test against.
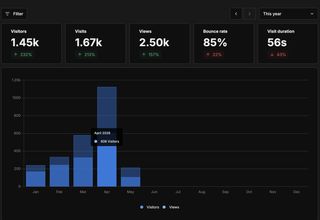
April 2026 blog traffic: 606 visitors and roughly 1.13k views.
I was surprised to find out that my blog traffic has been growing organically, with no marketing from me at all. Last month it had 606 visitors and roughly 1.13k views, which is a real WOAH moment for a personal site. Thanks to everyone who has been coming to my blog; I wish you all the best.
Neow's Cafe browsing catalog-backed card data instead of bundled mock cards.
I spent today turning ProjectSpire's iOS app "Neow's Cafe" from a mock-card browser into something much closer to a real Slay the Spire 2 card catalog.
The main decision was to keep the first version boring in the best way: a static, versioned catalog generated from the game data, served locally, and loaded directly by the app instead of inventing a REST API too early.
That structure gave the app one small index for browsing and filtering, while keeping full per-card files and portrait assets nearby for detail/debug views later. The important bit is that the card grid does not need to fetch hundreds of separate files just to show the collection.
`cards.index.json` is the grid, search, and filter payload. It contains all card summaries needed by the app:
- id
- slug
- title
- description
- energy cost
- type
- rarity
- pool
- portrait path
- optional detail path
Keep individual card JSON files for detail and debug views, not for the main grid.
On the Swift side, CardCatalogService.swift now loads manifest.json, follows it to cards.index.json, and decodes the catalog into app cards. I also removed the old bundled sample portraits, so the app is now much more dependent on the generated catalog behaving like the source of truth.
The Cards screen got some polish too: the catalog can be refreshed from the view, the grid is now a two-column layout that preserves the card aspect ratio in CardsView.swift, and I cleaned up the filter model so "no filter" is represented by optional UI state instead of fake .all enum cases (filter cleanup commit).
The other nice bit from today is process-oriented: ProjectSpire now has Captain Logs for collaboration notes and a reusable workflow for turning a day's commits and documentation changes into these timeline summaries. That should make it easier to keep writing about the work without having to rediscover the shape of the day from raw git history every time.
After a few weeks working on ProjectSpire with Codex, I’m leaning toward it as my default for software engineering projects. The main frustration has been hitting the Pro account limit; otherwise the quality has been good, the interaction feels responsive, and the output gives me instant feedback while it works. Claude Code still feels more like a black box to me: it can disappear into minutes of research and thinking on its own, and the effective limit feels lower. That tradeoff matters, because for this kind of project I want a tight engineering loop more than a long silent reasoning pass.
Shipped Card Parser v0.2.3 to ProjectSpire, which adds calculated variable resolution, numeric symbol extraction, and conditional text formatters. Cards like Ashen Strike now show computed damage values instead of raw placeholders, and I've added choose, cond, inverseDiff, and boolean formatters for rendering conditional card text. The parser now threads card type, target type, and runtime display vars (HasRider, Sapping, Energized, etc.) through text resolution, making the pipeline much more precise about card state and context.
The whole card parser has been built in this mode: I act as architect, GPT-5.5 acts as developer. Every meaningful parser improvement came from me inspecting concrete generated JSON against real card examples and asking source-fidelity questions. GPT-5.5 didn't discover that cost upgrades can be negative, or that Bash's upgraded Vulnerable value wasn't being applied, or that X-cost cards needed their own shape. I did, by reading the output and comparing it to what the game actually does.
The pattern that emerged: I'd spot a class of issue on a specific card, explain what the game source was doing and why the output was wrong, and GPT-5.5 would produce a working fix. Then I'd push to turn each discovery into a repeatable check rather than a one-off patch. The coverage audit script, the unresolved placeholder CSV, the hard failures on missing source files: all of those came from me steering toward systemic fixes after catching individual bugs.
What GPT-5.5 is good at in this loop is the mechanical throughput. Regex extraction, threading new state through a resolution pipeline, mirroring changes to the audit script, regenerating 55 JSON files, splitting work into clean commits. The domain knowledge, the quality bar, and the architectural decisions all come from the human side. GPT-5.5 doesn't know what CalculatedVar means in the game engine or why display vars like HasRider matter for conditional text. It doesn't need to, once I describe the shape of the problem clearly enough.
The productivity gain isn't just speed. It's that I can stay at the architectural level, thinking about which cards are still wrong and why, without losing momentum to implementation mechanics. The feedback loop stays tight: inspect, identify, describe, implement, verify, repeat.
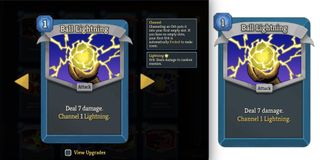
Here's what a fully resolved card looks like now. Ball Lightning's resolved block shows the base and upgraded display states, with structured text runs that carry source variable references and style annotations:
I shipped v1.32.1 of 11ty-subspace-builder to fix prose link wrapping on narrow screens. Very long URLs now wrap inside the content column instead of forcing the page wider than the mobile viewport, which keeps notes and posts readable even when a raw link has nowhere graceful to break.
I worked with GPT-5.5 on a reproducible Slay the Spire 2 resource extraction plan and then landed it in ProjectSpire across the recovery scripts, allowlist, generated resource subset, image-format experiment, and workflow docs.
The Principles matter more than the files: keep the full recovered dump local and ignored, track only curated resources with a current use, make extraction scriptable instead of manual, prefer readable Python tooling, keep binary assets repo-friendly with WebP and Git LFS, and write down the decisions close to the evidence.
The implementation follows that shape by keeping Lab/unpacked/ as the local source dump and generating Lab/resources/ from Lab/resources.allowlist.yaml, starting with localization plus WebP q85 card portraits.
That gives my STS2 projects inside the ProjectSpire monorepo access to assets like this at roughly a fraction of the original size, around 10%, without needing to commit the full recovered dump.
One of the recovered card portraits from the first curated resource subset.
I shipped generated Open Graph cards for the timeline in v1.32.0 of 11ty-subspace-builder. The root timeline page and individual timeline entries now get social preview images from generated card data, while static card metadata lives in site data so downstream projects can configure it without touching templates. I also updated the timeline docs to spell out how those preview images are selected.
I added a ProjectSpire design note in 399f74d that pushes the card pipeline toward a two-pass model: keep the parser output source-faithful, then resolve localization and rendered text separately for the app.
I created that work with GPT-5.5 in plan mode, and it asked a few genuinely useful clarification questions before I let it draft anything substantial, which made the whole process feel a lot more controlled than a blind codegen pass. I also pushed back on several of its first suggestions and made a lot of the consequential decisions myself, especially around keeping canonical variable names intact and separating raw data from resolved display data. That feels like a strong pattern for future ProjectSpire work: use the AI models to widen the search space, but keep the architecture decisions and edits grounded in my own judgment.
I published Slip, Slop, Slap vs. Going Pink: Why Australia and the UK Treat Sun Safety So Differently, a note on why Australia and the UK treat sun safety so differently and why the mortality numbers are more surprising than the incidence numbers. The observations are mine; AI handled the research and wrote the first draft, and I edited the result before publishing.
I published The Brain That Grew — Then Shrunk: What I Just Discovered, a long-form note that starts from a Cleo Abram YouTube Short and then follows the research on human brain evolution, the unexpected Holocene shrinkage, and the idea that culture may have taken over part of the cognitive load. It is the kind of rabbit hole post I like writing here: one short video, a lot of reading, and a sharper takeaway than I expected.
I’ve been working on ProjectSpire’s iOS app (codename: Neow’s Cafe) in NicholasClooney/ProjectSpire as a 1:1 Slay the Spire 2 card library, and the useful part is not just the filtering UI and refactor cleanup, but the way I’m trying to work with AI.
I get better results when I lay down the foundations myself first, especially around quality, guard rails, and how the data is modeled, and then let AI work inside that framework instead of asking it to define the framework for me. It also helps a lot when I have AI propose higher-level API or contract changes before it starts making edits.
Here's a snapshot of the visual changes. There is also quite a bit of non-visual work too, like reorganizing the source files into clearer areas such as App, Components, Models, Views, Logic, and Dependencies, splitting the banner text into its own component, moving the app toward injected dependencies instead of hardcoded wiring, and a few other things.
The useful part is not just the snippets themselves, but that AI agents researched the best practices, produced the example code, organized the project, and left me with a runnable playground where I can compare equal-width stacks, GeometryReader, PreferenceKey, and some surprisingly similar results against my actual needs.
I published The Confident Lie: What AI Got Wrong About @ViewBuilder, a SwiftUI debugging note that came out of the ProjectSpire card view work. It captures a small but useful lesson: body gets @ViewBuilder from the View protocol, but a custom computed some View property needs the annotation explicitly if I want an if without an else. The compiler was right, the AI was overconfident, and now the mistake is written down somewhere I can find again.
I’ve moved the SwiftUI card view forward by adding a real Card model, so even though the screen does not look dramatically different yet, the app is much closer to rendering cards from extracted data instead of hardcoded values. There is even a small visual regression in the golden text compared with the previous screenshot, but the important change is underneath: I can now refine the card parser and JSON output models, bring those records and required images directly into the app, and aim to emulate any card regardless of rarity, type, or data shape. The relevant work is in the ProjectSpire compare for the card view changes and the new card model.
New Card model version.Previous visual pass for comparison.
I’m really happy that I built the timeline feature into my blog, because it gives me an easy way to write about little moments and keep them somewhere permanent, platform agnostic, and accessible without any kind of paywall or login wall. The ProjectSpire SwiftUI card view WIP entry is exactly the kind of thing I wanted this for: a small progress record I can send to friends and family without needing it to be a full post or trapped inside a social feed.
I’m recreating the Slay the Spire 2 card view in SwiftUI with assets extracted from the game, and I’m very happy with how close the first pass feels. The current work is captured in ProjectSpire snapshot/2026-04-28, especially CardView.swift; most of it is still hardcoded, but the visual foundation is there. Next I want to generalize it so the view can take a card data object and dynamically reload the text, colors, and assets, which might eventually turn into a Slay the Spire wiki app for the phone.
I published Why You Feel More Tired During the Day Than at Night, a practical explanation of the afternoon slump, the evening second wind, and the push-pull between sleep pressure and circadian alerting. The useful takeaway is simple: protect sleep quality, get morning light, move during the day, and be deliberate about caffeine timing.
I published Localization Formatters - Slay The Spire 2 Research Note, a ProjectSpire note on how card localization formatter functions such as diff() are resolved and applied. GPT-5.5 researched and wrote the note, and I am honestly amazed by how well and how quickly it produced a detailed explanation from decompiled sources in minutes. This is exactly the kind of agent-assisted research loop that makes ProjectSpire feel much more possible.
I published Three ways to pass an @Observable object in SwiftUI, a short SwiftUI reference for choosing between environment injection, direct initializer passing, and @Binding. It keeps the distinction focused on ownership and coupling: whole-object reference sharing when the child is allowed to know the model, or a projected binding when the child should only see one value.
I pushed 1263f2d to SwiftyBites as a Friday-night AsyncDebounceDemo for playing with Swift's async and sync edges. The demo compares a view-owned async .task flow with a synchronous button action that cancels and restarts a stored Task, which makes the debounce mechanics feel a lot more concrete than just reading the pattern.
I updated SwiftUI in the Wild: Memory, Concurrency, and the Gaps in the Docs with a clearer explanation of using .task(id:) for debounced work. The change moves that pattern into the debounce section, where SwiftUI's automatic cancellation model fits naturally, and keeps the button-action section focused on manual task ownership tradeoffs.
I published Godot + .NET Internals: PCK Files, Dual Runtimes, and Why Decompiled C# Looks Terrible as a note for Slay the Spire 2 modding work. The useful distinction is that Godot mounts the .pck for its own virtual filesystem while CoreCLR loads the .dll from disk, which also explains why source recovered from the .pck reads cleaner than reconstructed C# from a decompiler.
I published SwiftUI in the Wild: Memory, Concurrency, and the Gaps in the Docs, a field guide to the parts of modern SwiftUI + concurrency that look clean in isolation but get messy in real apps. The post covers @State + @Observable lifetime bugs, debouncing with async/await, task ownership in views and buttons, closure capture cycles, and why @Observable and actor pull in different architectural directions.
I’ve been working since last night and today with agents to document how Slay the Spire 2 works, prototype a Spire API and a REST API on top of it, and shape a WIP card parser that turns C# into JSON structures. That work is captured in ProjectSpire snapshot/2026-04-19, which gives me a concrete snapshot of the game model and tooling so far.
I shipped dedicated archive index pages in v1.30.0 of 11ty-subspace-builder, including a timeline months index alongside the earlier weeks index. It also tightens up the shared archive navigation, which makes the timeline's growing set of month and week views feel more connected instead of like isolated pages.
I shipped a dedicated /timeline/weeks/ index in v1.29.0 of 11ty-subspace-builder. It groups both month-banded weeks and ISO calendar weeks by month, includes entry counts on each link, and makes the older week archive pages easier to browse without already knowing the exact week key.
I shipped timeline topic archive pages under /timeline/:topic/ in v1.28.0 of 11ty-subspace-builder. Topic tags on timeline entries now link into that namespace, which makes it easier to follow one thread of work across time without losing the main chronological feed.
I’m thinking about a timeline-specific tags page at /timeline/tags/<tag>/ so I can group related entries together and follow one topic across time without losing the chronological context. It would make the timeline feel a little more like a long-running notebook for a single idea instead of only a straight feed.
Shipped a fix for the timeline entry detail view in v1.27.1 of 11ty-subspace-builder. Earlier in thread now includes older siblings from the same branch and keeps the nearest prior entry closest to the current one instead of flipping the thread upside down.
Shipped GitHub-style collapse and expand controls for long Markdown code blocks in v1.27.0 of 11ty-subspace-builder. The release also reuses that shared copy-and-collapse behavior for regular fenced code blocks, which keeps the interaction consistent instead of treating Markdown blocks as a separate case.
I shipped month archive pages for timeline entries, month-banded week archive pages under /timeline/weeks/, and ISO calendar week archives in v1.26.0 of 11ty-subspace-builder. That gives the timeline a few more ways to browse older entries without flattening the chronological flow.
Published The Accelerated Speed of Creation, a reflection on how much faster the path from thought to shipped artifact has become with coding agents handling the translation layer around writing, blog workflow, and routine Git operations. I also kept the earlier Encoding My Blog Workflow for Coding Agents draft as a note rather than a post, because it was useful and concrete but still did not meet my standard for what the real piece needed to be.
Shipped theme mode control and delayed previews in v1.25.0 of 11ty-subspace-builder. The new theme switch adds explicit auto, light, and dark modes instead of treating the site theme as a hidden implementation detail, and delayed previews make hover previews configurable so they feel less jumpy when moving around a page.
rtc-bridge — TCP tunneling from a browser, explained is up. I wrote down the WebRTC signaling path, the node/coordinator/browser split, and the auth gap I think matters most before anyone uses it for sensitive services. I also compared it to my Tailscale + Caddy setup so the trade-offs stay concrete.
I split the blog editing rules into repo-local skills in 22c4d7d. post-and-note-workflow now makes the timeline-entry rule explicit, while frontmatter-editing routes posts/, notes/, and timeline/ to canonical front matter docs instead of burying that guidance in CLAUDE.blog.md. I also cleaned up timeline-entry so its tag guidance matches the repo defaults.
I published WebRTC — How it actually works as a note on how signaling, STUN/TURN, ICE, DTLS, and SRTP fit together. The useful framing here is that WebRTC is not just "peer-to-peer"; it is a browser-owned transport stack wrapped around signaling and fallback infrastructure you still have to run.
I published Smart AI Token Consumption as a note on matching model choice to task complexity instead of defaulting to the biggest model. It captures the split I keep using in practice: light models for mechanical work, stronger reasoning only when the problem actually needs it.
I published Getting Pulled Into the Ethereum Ecosystem (From a Digital Garden Perspective) after a 3am rabbit hole with Andrew about Ethereum, trust models, and what a markdown blog can borrow from a ledger. It is less a crypto post than a thinking-out-loud piece about verification, shared state, and the difference between controlling a history and publishing into one. I’m treating it as the first step toward a small on-chain/off-chain experiment rather than a full web3 shift.
Published the first follow-up entry in the new threaded timeline model.
Timeline entries can now point back to earlier entries, which turns the feed into more of a build log than a flat list. This update continues from the original timeline launch and marks the point where parent and follow-up relationships became part of the feature.
I’ve set up ProjectSpire Lab so I can run a script that pulls a decompiled copy of Slay the Spire 2 for local experimentation; the game code itself stays out of Git because I do not have a license to commit it. The setup lives in NicholasClooney/ProjectSpire. It gives me a clean foundation to build mod tooling from.
This grows out of Cloudflare Build Notifications via Email Routing and Email Worker, but I’m now moving the Email Worker out of the Cloudflare dashboard editor and into Git in NicholasClooney/cloudflare-email-to-webhook-worker. The goal is to keep the worker version controlled, review changes before deploys, test locally, and configure it with Wrangler instead of only editing it in the Cloudflare web UI. Right now it is still mostly Wrangler init plus the example email worker, but that is a solid foundation to build from.
I created git-activity in a631c98 so I can quickly answer "what have I been working on?" It walks a directory tree, finds the Git repos underneath it, and shows the latest log entries from each one in a single pass. It also supports a few filters, which is handy when I only want to review a slice of recent work; for example, from my projects folder I can run:
git-activity -r blog -m feat -x chore
That recursively scans repos, focuses on feature work, and leaves chores out of the list.
I moved the timeline-entry workflow into a repo-local skill in f7fceef. It now sits at .claude/skills/timeline-entry/SKILL.md, with the date/time quoting rules, status tags, and commit-based workflow close to the files it writes.
I published The Limits of AI and Where Humans Shine — a devlog about a tiny timeline sorting bug that turned into a useful comparison between AI confidence, runtime verification, and human judgement. It follows the fix from plausible-but-wrong timestamp changes to a quoted-date guard that keeps the timeline honest.
I added a /release skill to 11ty-subspace-builder in f1cb3a3. It captures the release ritual in one place: choose the semver bump, update package.json, commit chore: release vX.Y.Z, push, and create the GitHub release with the right title, body, and compare link.
I’m recording the ProjectSpire ideas now even though they’ve been rattling around for a while: an unofficial SpireAPI for mods, a REST layer on top of it, and a voice-command/accessibility layer that could eventually add Whisper-backed recognition and text-to-speech. Writing them down gives me one place to grow the monorepo instead of leaving the ideas scattered in my head.
Published What's Worth Keeping: On Humanness in the Age of AI — a post on what I've been thinking about since attending a thought experiment session on AI and skill erosion. It's about the parts of humanness I think are genuinely worth protecting — junior skill-building, critical thinking, forming a view before outsourcing it — and what I actually try to do in my own daily use of AI tools.
Added a personal timeline feed to the site. Markdown files in timeline/, same front matter as posts. Color is tag-driven: shipped goes green, published goes blue, thinking goes amber — no extra fields needed.
Added random month navigation in v1.3.0 of project-etho — a button that jumps to a random month's content rather than always landing on the latest. Good for surfacing older stuff without having to browse manually.
Published A Small Digital Garden That Feels Like Home — a reflective post on what it means to tend a personal site: slow accumulation, things planted for yourself rather than an audience, and why that feels different from posting anywhere else.
Fixed OG image generation for Chinese text in v1.21.1 of 11ty-subspace-builder — social cards were silently dropping CJK characters, now they render correctly.
Published a note on homemade hash browns, two ways — the kind of thing I keep wanting to look up and never find written the way I remember it, so I wrote it down myself.
Added copy buttons to long fenced code blocks in v1.21.0 of 11ty-subspace-builder. Short snippets don't get one — only blocks long enough that scrolling to copy is annoying.
Code blocks and GitHub embeds now follow the runtime theme in v1.19.0 of 11ty-subspace-builder. If a visitor switches between light and dark, the embeds switch with them rather than staying hardcoded.
Shipped a lightweight notes section in v1.19.0 of 11ty-subspace-builder — short-form content separate from posts, with its own collection and OG image support so each note gets a proper social card.
Starting a captain's log. Shipped things, published writing, half-formed thoughts — all in one place, in order, no categories needed. Let's see how it goes.