I was pixel peeping ProjectSpire against the actual game, comparing the original Slay the Spire PNG in-game with my app's q85 WebP version generated from that same source art.
Somehow, despite the game having the full-resolution PNG available, the card looks worse in-game than it does in my app.
My educated guess is that the game has its own processing and rendering pipeline, with its own constraints and reasons for the final image quality tradeoff.
I tagged a ProjectSpire snapshot for 2026-05-11, but this one feels different because I barely did any of the implementation myself.
My Codex usage is nearly gone, so Claude carried most of the work while I was busy elsewhere: parsers for relics, potions, events, and monsters; shared parser utilities; tests; and a few devlogs.
I haven't built the UIs I need to verify Claude's parser work against the actual game properly. So I don't have that confidence in its work yet without the validation.
I miss Codex and the clearer feedback loop, the back and forth, and...
Most importantly my own deeper understanding of how everything ties together.
Blade of Ink now rendering its purple description text correctly.
I shipped a tiny Neow's Cafe v0.3.1 bug fix in ProjectSpire: purple was missing from the mapped text colors, so purple inline card text had nothing to resolve to. Now purple is part of the text color map, and cards like Blade of Ink can render their description highlight properly.
Published Where Do Codex's Cached Tokens Come From?, a note explaining why Codex can report millions of cached tokens after a run even when the actual prompt context is much smaller. The useful bit is that Codex's append-only agent loop keeps earlier messages as an exact stable prefix, so cache hits accumulate across repeated model calls in the same session.
Colored description text flowing from the catalog into Neow's Cafe card details.
I shipped a small combined ProjectSpire release: Card Catalog v0.3.0 and Neow's Cafe v0.3.0 now carry colored inline description text through the catalog and into the SwiftUI card views. The visible change is small, but it closes the loop from parsed game text to rendered card detail: upgraded values and highlighted terms now show with the same kind of color signal the game uses.
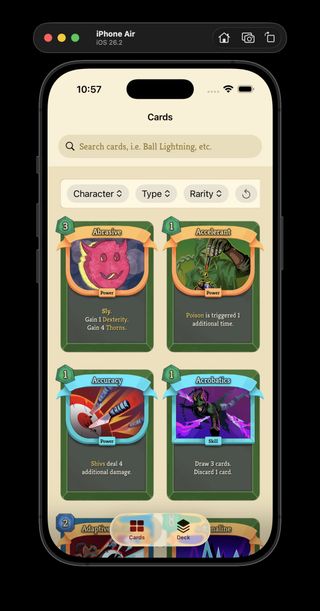
The catalog JSON now carries upgraded card values, and the app has a proper detailed card view where I can inspect those upgrades instead of only browsing the cards in their base form in the grid.
In the game, the numbers (17 and 5) in the text, would be highlighted with the color being green, because they are the upgraded from base values. That is next on my todo list.
Supress in the new detail view, with upgraded card data exposed from the catalog.
Almost running out of my weekly Codex / GPT token usage, so I switched to Claude for a few hours.
Somehow the experience feels much higher friction.
It likes to spend a long time thinking even for relatively simple tasks. For example: "write this devlog for me." It already had detailed guidance (ProjectSpire Devlogs CLAUDE.md) plus example documents in the same folder.
If it were GPT, it probably would have been done in seconds. Claude spent nearly a minute still "flabbergasting..." until I stopped it and asked what it was doing. Its response was essentially: "I was reading unnecessary documents."
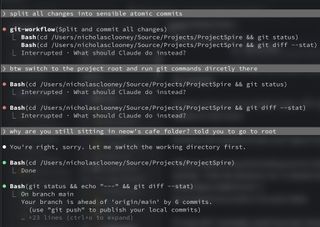
Then there's the terminal behavior.
I wanted it to run some git commands, but it kept doing cd project-root && git ... everywhere. I genuinely do not understand why, because it can already execute commands from within the project context directly.
Claude, Claude, Claude...
I explicitly told it: "cd into the project root once and then run git commands directly without repeating cd." Nope. It still kept issuing (cd ... && git ...) commands until I corrected it a second time.
I'm genuinely having a hard time getting used to working with Claude. Curious what other people's experiences have been.
The parser now extracts keyword references from card text and populates a keywords field in the generated JSON, which the app picks up and renders as keyword pills on card detail views.
Status and curse cards were the most visibly broken before this: they had no keywords at all, which made a whole class of cards feel incomplete in the UI. The research behind this lives in Lab Doc 0014, which covers how keyword matching works against the game's localization data.