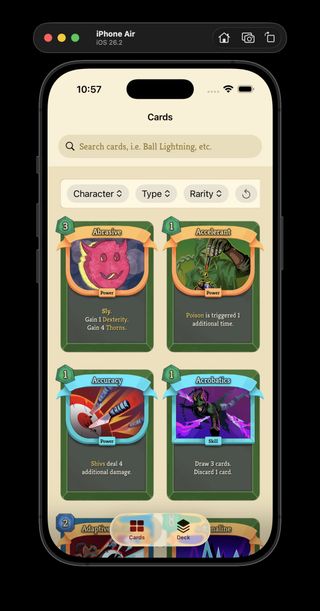
Blade of Ink now rendering its purple description text correctly.
I shipped a tiny Neow's Cafe v0.3.1 bug fix in ProjectSpire: purple was missing from the mapped text colors, so purple inline card text had nothing to resolve to. Now purple is part of the text color map, and cards like Blade of Ink can render their description highlight properly.
Published Where Do Codex's Cached Tokens Come From?, a note explaining why Codex can report millions of cached tokens after a run even when the actual prompt context is much smaller. The useful bit is that Codex's append-only agent loop keeps earlier messages as an exact stable prefix, so cache hits accumulate across repeated model calls in the same session.
Colored description text flowing from the catalog into Neow's Cafe card details.
I shipped a small combined ProjectSpire release: Card Catalog v0.3.0 and Neow's Cafe v0.3.0 now carry colored inline description text through the catalog and into the SwiftUI card views. The visible change is small, but it closes the loop from parsed game text to rendered card detail: upgraded values and highlighted terms now show with the same kind of color signal the game uses.
The catalog JSON now carries upgraded card values, and the app has a proper detailed card view where I can inspect those upgrades instead of only browsing the cards in their base form in the grid.
In the game, the numbers (17 and 5) in the text, would be highlighted with the color being green, because they are the upgraded from base values. That is next on my todo list.
Supress in the new detail view, with upgraded card data exposed from the catalog.
Almost running out of my weekly Codex / GPT token usage, so I switched to Claude for a few hours.
Somehow the experience feels much higher friction.
It likes to spend a long time thinking even for relatively simple tasks. For example: "write this devlog for me." It already had detailed guidance (ProjectSpire Devlogs CLAUDE.md) plus example documents in the same folder.
If it were GPT, it probably would have been done in seconds. Claude spent nearly a minute still "flabbergasting..." until I stopped it and asked what it was doing. Its response was essentially: "I was reading unnecessary documents."
Then there's the terminal behavior.
I wanted it to run some git commands, but it kept doing cd project-root && git ... everywhere. I genuinely do not understand why, because it can already execute commands from within the project context directly.
Claude, Claude, Claude...
I explicitly told it: "cd into the project root once and then run git commands directly without repeating cd." Nope. It still kept issuing (cd ... && git ...) commands until I corrected it a second time.
I'm genuinely having a hard time getting used to working with Claude. Curious what other people's experiences have been.
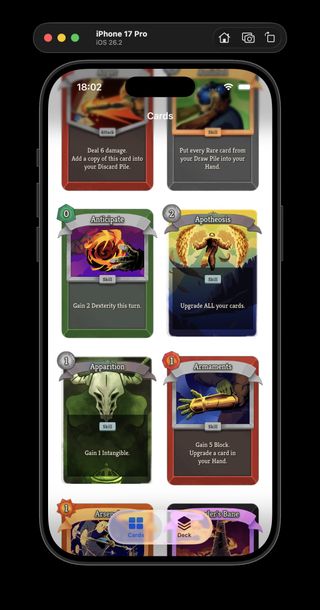
The parser now extracts keyword references from card text and populates a keywords field in the generated JSON, which the app picks up and renders as keyword pills on card detail views.
Status and curse cards were the most visibly broken before this: they had no keywords at all, which made a whole class of cards feel incomplete in the UI. The research behind this lives in Lab Doc 0014, which covers how keyword matching works against the game's localization data.
Neow's Cafe with the new light and dark app themes side by side.
I shipped another Neow's Cafe UI pass in ProjectSpire, focused on turning the app's visual styling into reusable systems instead of one-off view code. The work in the May 7 snapshot registers the app fonts as a typography system so I can use consistent text styles anywhere in SwiftUI, and adds explicit light and dark themes for the card catalog UI. It is a small-looking change, but it gives the app a much cleaner foundation for future screens.
It uses ProjectSpire as the working example: instructions as project memory, plans for intent, Captain Logs for collaboration taste, devlogs for technical history, and skills or workflows for repeated mechanical steps.
The useful idea is that the repo should accumulate context as it is used, so the human still supplies the judgment, but the surrounding system gets better at carrying that judgment forward.
I shipped v1.33.0 of 11ty-subspace-builder, adding wrap toggles to Markdown code blocks and GitHub embeds. Markdown code blocks now wrap by default, including Markdown files rendered through GitHub embeds, while collapsed GitHub embeds still allow long lines to scroll horizontally. I also added a draft regression page for long GitHub and Markdown code lines so this behavior has a concrete page to test against.
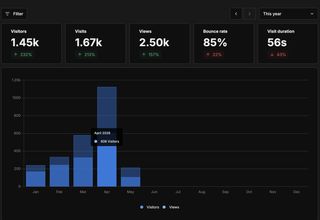
April 2026 blog traffic: 606 visitors and roughly 1.13k views.
I was surprised to find out that my blog traffic has been growing organically, with no marketing from me at all. Last month it had 606 visitors and roughly 1.13k views, which is a real WOAH moment for a personal site. Thanks to everyone who has been coming to my blog; I wish you all the best.
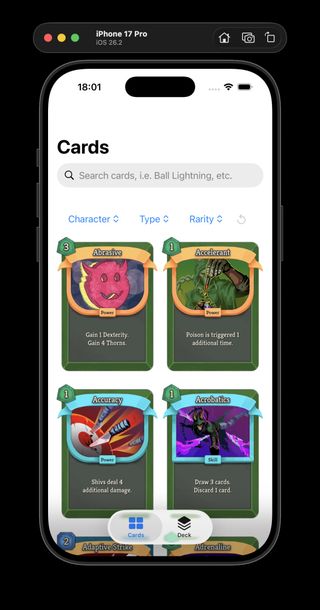
Neow's Cafe browsing catalog-backed card data instead of bundled mock cards.
I spent today turning ProjectSpire's iOS app "Neow's Cafe" from a mock-card browser into something much closer to a real Slay the Spire 2 card catalog.
The main decision was to keep the first version boring in the best way: a static, versioned catalog generated from the game data, served locally, and loaded directly by the app instead of inventing a REST API too early.
That structure gave the app one small index for browsing and filtering, while keeping full per-card files and portrait assets nearby for detail/debug views later. The important bit is that the card grid does not need to fetch hundreds of separate files just to show the collection.
`cards.index.json` is the grid, search, and filter payload. It contains all card summaries needed by the app:
- id
- slug
- title
- description
- energy cost
- type
- rarity
- pool
- portrait path
- optional detail path
Keep individual card JSON files for detail and debug views, not for the main grid.
On the Swift side, CardCatalogService.swift now loads manifest.json, follows it to cards.index.json, and decodes the catalog into app cards. I also removed the old bundled sample portraits, so the app is now much more dependent on the generated catalog behaving like the source of truth.
The Cards screen got some polish too: the catalog can be refreshed from the view, the grid is now a two-column layout that preserves the card aspect ratio in CardsView.swift, and I cleaned up the filter model so "no filter" is represented by optional UI state instead of fake .all enum cases (filter cleanup commit).
The other nice bit from today is process-oriented: ProjectSpire now has Captain Logs for collaboration notes and a reusable workflow for turning a day's commits and documentation changes into these timeline summaries. That should make it easier to keep writing about the work without having to rediscover the shape of the day from raw git history every time.
After a few weeks working on ProjectSpire with Codex, I’m leaning toward it as my default for software engineering projects. The main frustration has been hitting the Pro account limit; otherwise the quality has been good, the interaction feels responsive, and the output gives me instant feedback while it works. Claude Code still feels more like a black box to me: it can disappear into minutes of research and thinking on its own, and the effective limit feels lower. That tradeoff matters, because for this kind of project I want a tight engineering loop more than a long silent reasoning pass.
Shipped Card Parser v0.2.3 to ProjectSpire, which adds calculated variable resolution, numeric symbol extraction, and conditional text formatters. Cards like Ashen Strike now show computed damage values instead of raw placeholders, and I've added choose, cond, inverseDiff, and boolean formatters for rendering conditional card text. The parser now threads card type, target type, and runtime display vars (HasRider, Sapping, Energized, etc.) through text resolution, making the pipeline much more precise about card state and context.
The whole card parser has been built in this mode: I act as architect, GPT-5.5 acts as developer. Every meaningful parser improvement came from me inspecting concrete generated JSON against real card examples and asking source-fidelity questions. GPT-5.5 didn't discover that cost upgrades can be negative, or that Bash's upgraded Vulnerable value wasn't being applied, or that X-cost cards needed their own shape. I did, by reading the output and comparing it to what the game actually does.
The pattern that emerged: I'd spot a class of issue on a specific card, explain what the game source was doing and why the output was wrong, and GPT-5.5 would produce a working fix. Then I'd push to turn each discovery into a repeatable check rather than a one-off patch. The coverage audit script, the unresolved placeholder CSV, the hard failures on missing source files: all of those came from me steering toward systemic fixes after catching individual bugs.
What GPT-5.5 is good at in this loop is the mechanical throughput. Regex extraction, threading new state through a resolution pipeline, mirroring changes to the audit script, regenerating 55 JSON files, splitting work into clean commits. The domain knowledge, the quality bar, and the architectural decisions all come from the human side. GPT-5.5 doesn't know what CalculatedVar means in the game engine or why display vars like HasRider matter for conditional text. It doesn't need to, once I describe the shape of the problem clearly enough.
The productivity gain isn't just speed. It's that I can stay at the architectural level, thinking about which cards are still wrong and why, without losing momentum to implementation mechanics. The feedback loop stays tight: inspect, identify, describe, implement, verify, repeat.
Here's what a fully resolved card looks like now. Ball Lightning's resolved block shows the base and upgraded display states, with structured text runs that carry source variable references and style annotations: